Apache Hudi를 사용해서 Hudi 테이블을 만들어서 운영할 때 Hudi 테이블을 Hive 테이블로도 만들어서 사용하고 싶을 수 있다. Apache Hudi에 대한 소개는 이곳은 참고 : Apache Hudi 소개 일단 Hive 테이블로도 만들어두면 데이터를 확인하는 것이 간편하다. Hive Metastore에 테이블을 등록해두면 Spark 또는 Hive로 덜 번거롭게 데이터를 확인해볼 수 있기 때문이다. Hive Sync를 한다는 것은 Hudi 테이블 경로를 location으로 하는 Hive 테이블을 생성하거나 스키마를 동기화한다는 것을 의미한다. Hudi 테이블 데이터를 복제하여 새롭게 Hive 테이블용 데이터를 생성하고 복제된 데이터를 location으로 하는 Hive 테이블을 만든다는 것은 ..
HDFS의 특정 디렉토리의 파일 갯수를 알고 싶을 때가 있다. 그럴 때 사용할 수 있는 명령어이다. hdfs dfs -count {path} # 1000개를 K 단위로 바꾸어서 보여준다 hdfs dfs -count -h {path} 특정 디렉토리 내 하위 디렉토리들의 정보를 다음과 같이 한번에 조회할 수도 있다. hdfs dfs -count hdfs://path/to/count/* 조건을 잘 설정하면 특정 문자로 시작하는 디렉토리만 조회하는 등의 응용도 가능하다.
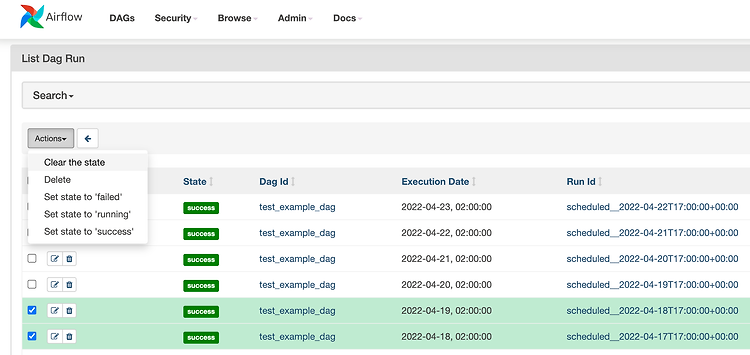
Apache Airflow을 구축해서 운영하다보면 이런저런 이유들로 인해 DAG을 재수행해야하는 일이 발생한다. raw 데이터 오류, 집계 로직 오류 등의 이유로.. 재수행하는 방법에 대해서 정리해본다. 일단 크게 DAG run 단위로 재수행하거나 task 단위로 재수행하는 방법으로 구분할 수 있을 것 같다. # DAG run clear 하기 DAG run을 clear해서 DAG run이 다시 수행되게 하는 방법이다. DAG run을 눌러 나오는 Clear 버튼을 눌러 clear하면 해당 DAG run이 재수행된다. 상단의 Browse > DAG Runs 메뉴에서 목록으로 DAG run을 조회하여 Clear the status 버튼을 통해 Clear하는 방법도 가능하다. # Task clear 하기 ta..
Apache Airflow의 DAG 내에 task들의 dependency를 설정함으로써 task 실행 순서와 병렬 실행 task들 등을 정의할 수 있는데, Airflow를 조금이라도 사용해 봤다면 이것은 당연히 알 것이다. 그리고 Airflow에서는 2.1 버전부터 DAG 내 task들 뿐만 아니라 DAG 간의 dependency를 설정할 수 있는 기능도 제공한다. 설정할 필요성을 생각해보면, A라는 DAG이 B라는 DAG 로직에서 생성한 데이터가 있어야만 정상적으로 수행 가능하다고 하자. 그러면 B DAG의 수행 시간(schedule_interval)을 A DAG이 일반적으로 종료되는 시간 이후로 설정하는 방법이 있는데 충분히 여유를 두고 설정하더라도 A DAG 수행이 모종의 이유로 특별히 오래 걸렸다..
HDFS는 RDBMS와는 다르게 기존 데이터를 업데이트해서 사용하는데 적합하지 않다. 하지만 로그성 데이터가 아니라 상태값이나 변할 수 있는 값을 가지는 데이터인 경우 변경 사항이 계속 발생하고 이것을 주기적으로 반영해야할 필요성이 있을 수 있다. 예를 들어 상품 판매 순위를 집계하려면, 상품 판매 로그와 상품 자체에 대한 정보가 있어야 한다. (로그에 상품에 대한 정보를 포함시킬 수도 있지만 최신 정보를 얻으려면 별도 정보가 필요할 것이다.) 로그는 변하지 않는 데이터이지만 상품에 대한 정보는 상품명, 카테고리 등이 계속 변할 수 있다. 이런 경우 데이터 전체 크기가 그렇게 크지 않은 경우 전체 데이터를 주기적으로 새로 dump할 수 있다. (Sqoop 등을 활용해서) 하지만 전체 데이터 크기가 커서 ..
에이브로 (Avro) 아파치 에이브로는 더그 커팅이 개발한 언어에 중립적인 스키마 기반의 데이터 직렬화 프레임워크이다. 데이터를 네트워크를 통해 전송하거나 저장하기 위해서는 데이터를 직렬화해야한다. 하둡 Writable 클래스들은 언어 이식성이 없기 때문에 에이브로는 하둡에서 데이터를 직렬화하는데 선호되는 도구이다. 스키마 스키마는 JSON을 사용하여 정의된다 [User에 대한 스키마 예제 (user.avsc)] { "namespace": "example.avro", "type": "record", "name": "User", "fields": [ {"name": "name", "type": "string"}, {"name": "favorite_number", "type": ["int", "null"]}..